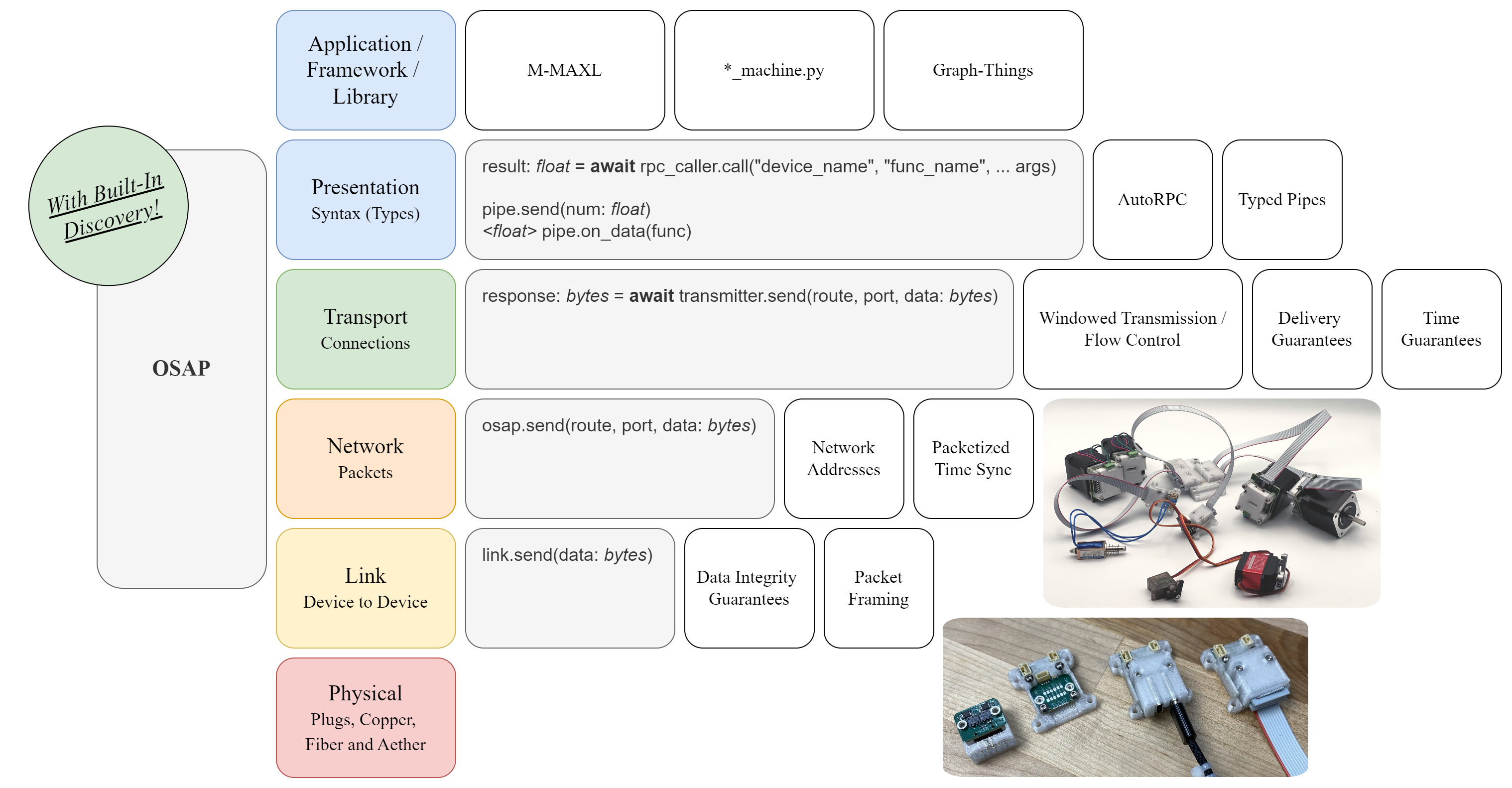
2 OSAP: Machine Systems Interconnect
2.1 Chapter Introduction
In the simplest sense, GCode just a way to communicate with machines. Our main frustration with it is that it splits our computational representation of machines: we have components of our workflows above and below GCode, but these are not connected. So our first key goal is to develop a systems architecture that lets us connect software components in the realtime “control” domain with the higher level “planning and tasking” domain. Taking a cue from software design, we also want to build these larger systems from a reuseable set of components (motor drivers, sensors, control software, planning software etc). The main challenge here is to develop an architecture that is descriptive and broad enough to include all of the required parts, but that does not introduce an amount of computing overhead that would prevent us from doing performant, realtime control.
We also want to build machine systems out of modular components. Doing so lets us re-use modules across projects, letting us quickly compose new systems from the parts bin rather than re-engineering circuits, drivers and code. The best way we know to do this is to build networked control systems, putting a small computer (a microcontroller, aka MCU, aka \(\mu c\)) on each ouput and input device and then allowing them to pass messages to one another. In this section, I describe my methods in developing the lower layer of that control system, which transports messages from component to component.
2.1.1 Machine Building Needs Flexible Network Architectures
OSAP follows the Open Systems Interconnect model (Standardization 1994) which is guided by the end-to-end principle (Saltzer, Reed, and Clark 1984), both of which were foundational during the invention and proliferation of the internet, but neither of which have been rigorously followed in the internet’s development (Group 2019). The OSI model was meant to enable broad connectivity across heterogeneous link layers, but in practice the field of internetworking in hardware (and in industrial machine systems in particular) is fractured.
Machine-scale modular hardware systems (of the kind we deploy in this thesis) are deployed on a heterogeneity of different network links and transport layers (Lian, Moyne, and Tilbury 2001) whereas the internet is dominated by only a few (TCP, Ethernet, WiFi, etc). That heterogeneity means that we really need the OSI model to work moreso for automation than we do in the internet.
Many different networking technologies exist for machine control for the same reason that many different types of machines exist: the physical world is itself heterogeneous. Sometimes we want networks to be cheap, sometimes we want them to be extremely performant, sometimes noise immunity is critical, and other times it is not. This leads to the development of different networking technologies. Because embedded devices are low on computing power, building clean interfaces between layers in the OSI model (layer abstractions add computing and memory overhead), is not top-of-mind for automation engineers. Because machines tend not to be required to integrate within larger newtorks (local architectural divergence is OK), there is little pressure to develop interoperability across network types and topology.
As a result, industrial network stacks tend to collapse many layers in the OSI model into just one or two. CAN bus [-bosch1991can] (common in automobiles) is perhaps the best example: we can only run CAN-type application layers on CAN busses, i.e. CANopen (2011) and J1939 (2024).
With OSAP, I try to develop an architecture that allows for this heterogeneity of link layer technologies by developing a link-layer software interface (Section 2.2.3.1). In Section 4.3 I demonstrate how this could be extended physically, to allow hardware reconfigurability across links.
2.1.2 Background in Mechatronic Systems Architecture
The work in this thesis is enabled by a flexible machine control architecture that combines modular hardware with software. This model was originally formalized by (Peek 2016) and (Moyer 2013) at the CBA as Object Oriented Hardware, which is relevant background in this and in the next chapter. The CBA also has a history of developing small networks for inter-device internetworking (Gershenfeld, Krikorian, and Cohen 2004) and building modular robotics (Smith 2023) (Abdel-Rahman et al. 2022). Work on modular physical computing is active in the HCI community (Devine et al. 2022) (Ball et al. 2024).
OSAP also extends other modular physical computing frameworks by enabling the use of a multitude of link-layers, whereas i.e. JacDac and Gestalt are limited to custom embedded busses.
Developing networks for real-time systems is itself a challenge, luckily there is well established practice in this domain. In particular, I borrow a scheduling pattern from (Di Natale 2000) and clock synchronization patterns from Network Time Protocol (Mills 1991) and high-performance counterpart (Eidson, Fischer, and White 2002), and other simple approaches (Ciuffoletti 1994). I have also studied simpler approaches from explicitly real-time domain (Kopetz and Ochsenreiter 1987).
A complete review of these is outside of the scope of this thesis; I present OSAP primarily as a methods section so that we can understand how other components of the thesis operate.
2.2 OSAP
OSAP (for Open Systems Assembly Protocol) is a relatively lightweight piece of software that I have authored in C++ for embedded devices and in Python for high-level system components. It includes a runtime where messages are queued and handled (Section 2.2.2) and software interfaces up into software (Section 2.2.3.3) and down to network drivers (Section 2.2.3.1). Because it mediates between hardware and software, and does so across networks (where the real “underlying hardware” is the network itself), it is akin to a distributed operating system. I discuss whether or not it really deserves this title in Section 2.4.4.
The networking is link agnostic, meaning that it can be extended across many types of networking technologies with relatively little overhead. Because OSAP is a protocol and design spec, it should be easy to author in other languages when i.e. we want to build versions that provide handles to software written in Rust or JavaScript, or even into hardware design languages for custom silicon or FPGAs.
OSAP’s main task is to get serialized messages from any port in the system to any other port in a timely manner. It also provides two valuable services. Section 2.2.4.1 describes the discovery service which allows any device to retrieve a network map of connected devices. This allows us to inspect networks and determine i.e. if the motor drivers that our machine needs are, in fact, connected (and how to reach them). Section 2.2.4.2 describes the time synchronization service, which keeps device clocks in step with one another. This is a critical building block for mechatronic systems since it lets us synchronize motion, measure real network performance, and collect coherent time series data from networks of sensors and actuators.
OSAP is not itself semantically meaningful, in the same way that IP addresses are not; this is the layer where we get the bytes from one place to another. For the layer where we make sense and structure out of those bytes, see Section 3.2. For the layer where those structures are used to make motion control work, see Section 3.3.
2.2.1 Design Goals
OSAP is based on a thread of research that goes back tens of years in the CBA’s history based on object oriented hardware, that pairs modular hardware with modular software. I aimed to expand this architecture to span a broader heterogeneity of components and network configurations, to more easily add new firwmares and software integrations, and to enable the development of inter-device data flows (as opposed to star-shaped or bus controller topologies). The design goals are simple:
- Be fast: handle messages quickly, without much computing overhead.
- Be simple: do not introduce excess programming burden, and do not consume excess program storage or RAM.
- Be reliable.
- Be flexible: run in many computing environments, different \(\mu c\)’s, and provide value in both high- and low-level systems.
- Be inspectable: allow us to ascertain network states remotely, to debug inevitably messy networked systems.
2.2.2 Runtime
OSAP’s internal structure has three key elements:
- A list of Ports, which are interfaces to software. These can be instantiated in software as classes (python) or by writing new classes that inherit from the base
Portclass (in c++). - A list of LinkGateways, which are interfaces to network drivers. Same instantiation rules as Ports.
- A stack of Packets. This has virtually unlimited length in python but is compiled to a fixed size in embedded systems, where memory management must be done carefully.
It also has properties:
- A unique Name, which can be remotely re-written, and is saved into non-volatile memory.
- A module-type Name.
- A version number.
OSAP runs a main loop. On each cycle of this loop, a number of tasks are executed.
- Run
loopfunctions for all Ports and Links. - Collect Packets from the stack and sort them according to the earliest deadline (messages that are closest to timing out are handled first)(2000). In this step we de-allocate packets that have timed out.
- Handle each packet:
- For packets addressed to Ports, extract and reverse the Route (2.2.3.2) and the Source Port Index, and call the receiving Port’s
on_packetfunction. De-allocate the packet. - For packets that should be forwarded through the network, read the next routing instruction, assess whether or not that LinkGateway is clear to transmit, and either hand the message to that Link (when open, de-allocating the packet in this case), or continue (leave it in memory for the next loop cycle).
- For timing service packets 2.2.4.2, perform the time sync routine and then return the packet to sender.
- For packets addressed to Ports, extract and reverse the Route (2.2.3.2) and the Source Port Index, and call the receiving Port’s
This is the core of the runtime. Effectively we are using packet queue’ing and scheduling as a proxy for task scheduling.
2.2.3 Layers
2.2.3.1 Links
Link drivers, which instantiate (python) or inherit (c++) the LinkGateway class, are responsible for managing their link layer. This includes:
- Framing packets such that they can be delineated on whichever PHY they are operating by the Link on the other side of it.
- Ensuring that data in received packets is not corrupted, this un-burdens the runtime from having to perpetually anticipate or check for malformed data.
In this thesis, I use USB-CDC class links alongside a simple link that I developed which transmits UART over RS485. I have also tested UDP-based links, and prior versions of OSAP included provisions for busses, wherein I used a UART-based bus protocol.
2.2.3.2 Networking
Links in a runtime are instatiated in an ordered list. Packets contain bytecode instructions in their headers1. One of these instructions is link_forward, which has an argument for which link index, in the runtime of arrival, the message should be sent along. The first byte in the packet is a pointer that which indicates which instruction should be executed next. This means that we can do:
// the opcode occupies only the first two bits of any byte in the header,
uint8_t instruction = pck->data[pck->data[0]] >> 6; When a link ingests a packet, it increments this pointer so that the runtime will know what to do with it in the next loop and then inserts it’s own index (link address) into the packet at the previously-pointed-to instruction. This enables us to reverse the route at any time, to reply to senders without having to ascertain network state. So, rather than using routers, lookup tables and device addresses for networking, write routes into packets at their source, a strategy aptly named Source Routing (Sunshine 1977).
Packets also contain a time to live (TTL) stamp, which is measured in microseconds. When the link ingests the packet, it calculates that message’s scheduling deadline as the packet arrival time + TTL. The TTL is configured by message senders, and roughly encodes priority: packets with tighter TTL will be handled earlier. (Di Natale 2000) found that this is favourable in overall network performance than priority-based scheduling, where it is often the case that one priority level will become crowded with messages that cannot be prioritized otherwise.
Besides the link_forward opcode, we also have:
datagram- the message is in its destination runtime and should be passed to a Port. Arguments are the packet’s Source Port Index and Destination Port Index.bus_forward- a protocol provision for the inclusion of busses. Arguments are the forwarding busses’ index in the current runtime, and the address (on that bus) of the receiving runtime, or a broadcast subnet.system_message- for network service related messages: currently this only includes the time service 2.2.4.2, the DNS 2.2.4.1 is runs within a Port, at Port Index = 0.
2.2.3.3 Ports
Ports receive messages from the network as I described in Section 2.2.2. They can transmit messages at any time, specifying a network route, receiving port index, and a datagram to send.
2.2.3.4 Transport
Transport codes are implemented between ports (which are stateless) and software (which may want i.e. delivery guarantees, timing guarantees, sequence guarantees, or to frame large messages over a series of packets). The first byte in any packet’s data frame is a transport_key, which ID’s the type of transport layer that the message is sent by. This is a provision to deconflict transport layers, so that i.e. messages that are improperly addressed can be handled appropriately.
So far I have only authored two of these: a Sequential Transmitter and Receiver, which provide order-of-delivery guarantees and allow us to easily reply to a particular message, which helps software to ensure that (for example) responses to particular RPC calls (Section 3.2.2.2) are resolved against the correct call.
2.2.4 OSAP Services
2.2.4.1 Network Discovery
OSAP Runtimes can implement a “netresponder” class on their 0th port. These reply to queries made by “netrunner” instances in other devices, which are responsible for ascertaining global network state. I outfit a series of queries here:
- Get Runtime Information
- Get Module Type Name
- Get Module Name
- Set Module Name
- Get Link Information
- Get Port Information
- Get Debug Messages
- Set Debug Vebosity
- Get Time Controller Configuration
- Set Time Controller Configuration
To collect network state, the netrunner sequentially updates configurations. This is done with a breadth-first search, querying runtimes to ascertain how many links they have, and then each link to ascertain whether it is open or closed, and then searching down this layer in the next cycle.
OSAP allows that there can be multiple paths to the same devices, which may be beneficial in control systems where we would want to send data on one link, and receive it on another (to increase overall throughput and reduce latency). To de-conflict loops, the Get Runtime Information message cycles a UUID that is transmitted by the netrunner, if the netrunner sees a UUID that it previously generated in another lookup, it knows that the device is connected in a loop.
2.2.4.2 Distributed Time Synchronization
OSAP provides a clock synchronization service, which is used as a basis for motion control and for time series data collection. Since other clock sync algorithms are complex and consume large amounts of program memory, I developed a simple version that is loosely based on well understood principles from the well establised Network Time Protocol (NTP, (1991)) and Precision Time Protocol (2002), but also on (Ciuffoletti 1994), where diffusion is used as a basis for synchronization.
Time is measured in microseconds, using uint64_t to eliminate overflows. Runtimes request time stamps from neighbouring devices at some configured interval (I use \(50ms\) in most networks). Those packets contain the local timestamp of the transmitter (when the packet was sent) the system time estimation from the receiver (when the packet was handled), and the receiver’s clock tier. When a runtime gets a time response, it:
- Calculates the round-trip-time, and estimates its partner’s current system time estimate, \(t_{p,now} = t_{p,stamp} + \frac{1}{2}rtt\).
- Measures the offset from its own current system-time estimate.
- Applies an exponetial weighted average to the offset estimation, and stores that estimate for each local partner, along with its clock tier.
We can then select a neighbouring clock:
- Pick the clock with the highest tier.
- Update our tier to be that clock’s tier plus one.
- If multiple neighbours have the same tier, compute the average of our offset estimations to each.
Using these estimates, we run a simple PI controller over our clock skew, shimming it up to catch up to neighbours or down if we are overrunning. Parameters for the clock’s PI controller and the offset estimation filter are tune-able via the netrunner / netresponder interface.
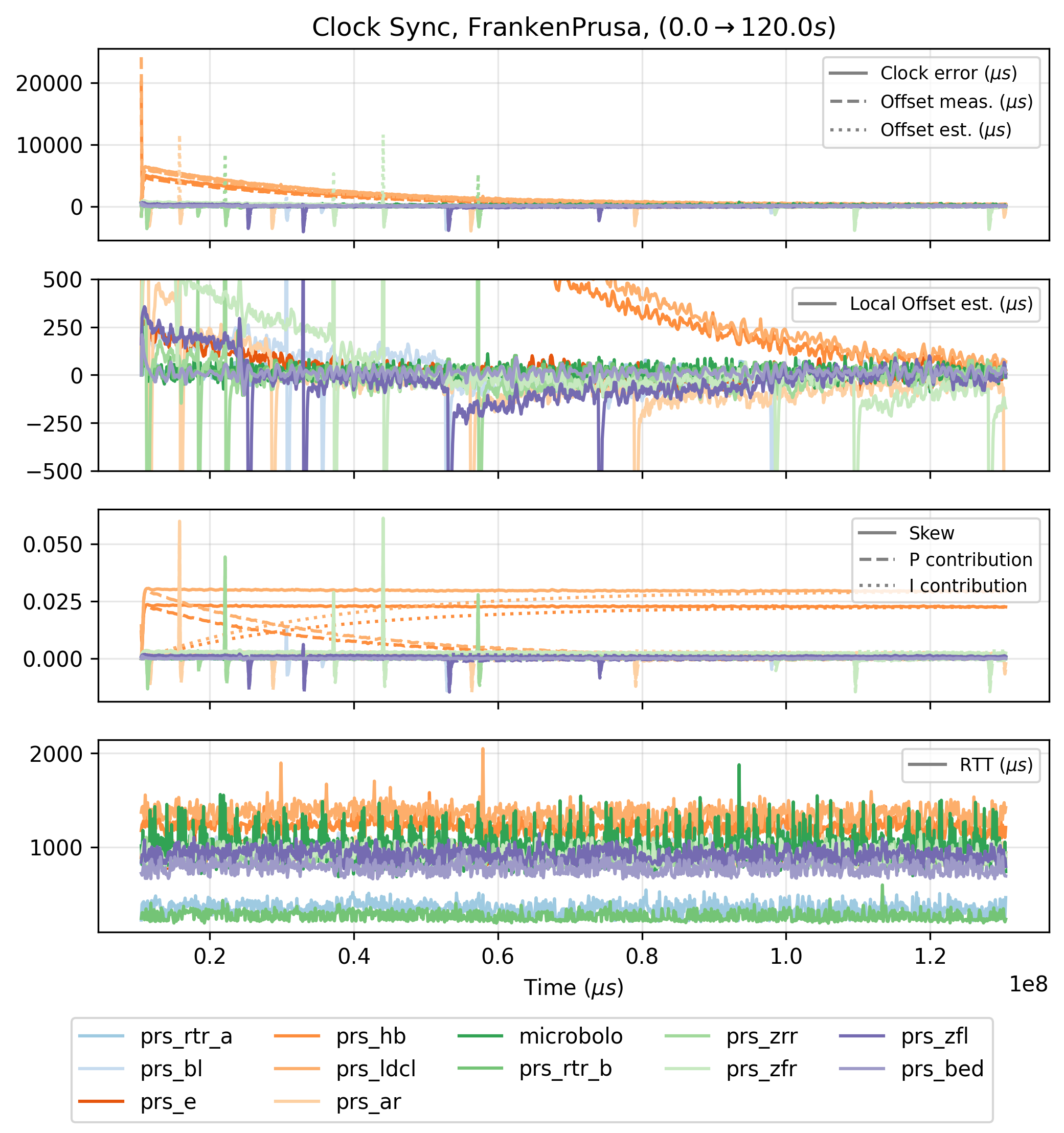
In the test above, we can see that clocks adjust to within \(500\mu s\) with one another after \(60s\) and within \(250\mu s\) after \(100s\) - and get better over time. Two caveats, the first being the rather obvious disturbances on these plots, where it seems that the controllers are being kicked out of band momentarily - I discuss this in Section 2.4.3. The second is that \(60s\) is a long time to wait for acceptable clock synchronization. To ameliorate this, we can hot start the synchronization controller, by storing clock skews after longer time synchronization runs and re-loading them into firmware when the system is initialized.
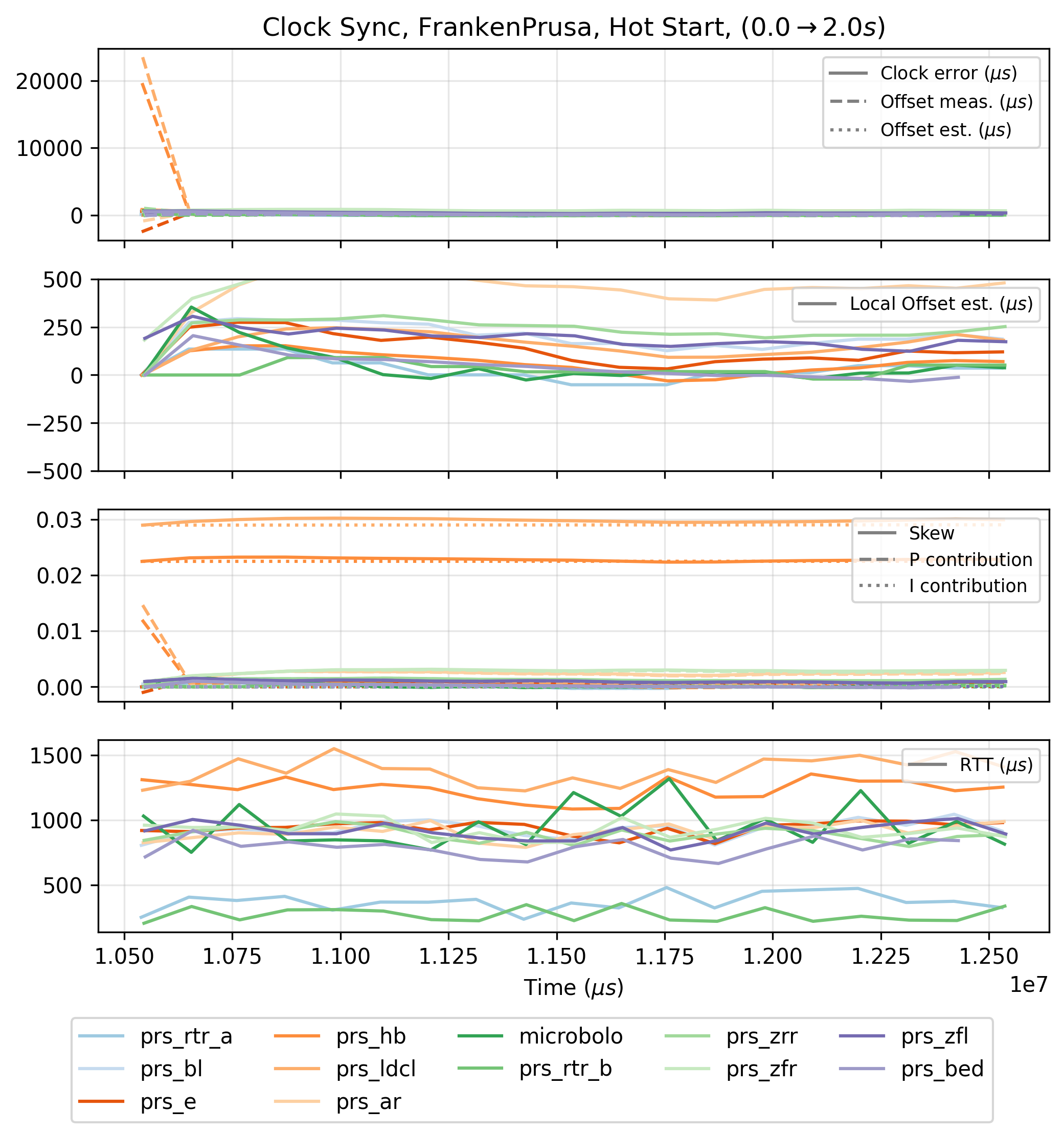
Overall, the synchronization in OSAP works well enough for me to complete all of the tasks in this thesis. It is clearly not perfect, and high performance synchronization is a requirement of advanced control systems. I discuss future work on the topic in Section 2.4.3.
2.3 Deploying OSAP
I use OSAP throughout this thesis. It’s runtime is the environment where PIPES and MAXL are built (Chapter 3) and that runs within all of my own circuit (Chapter 4) and others (see 4.5.3). It also powered earlier, simpler modular systems like the one we developed in (Read et al. 2023).
To segue into the next chapter on programming models for these systems, I want to show a complete system graph - this is for the FrankenPrusa.
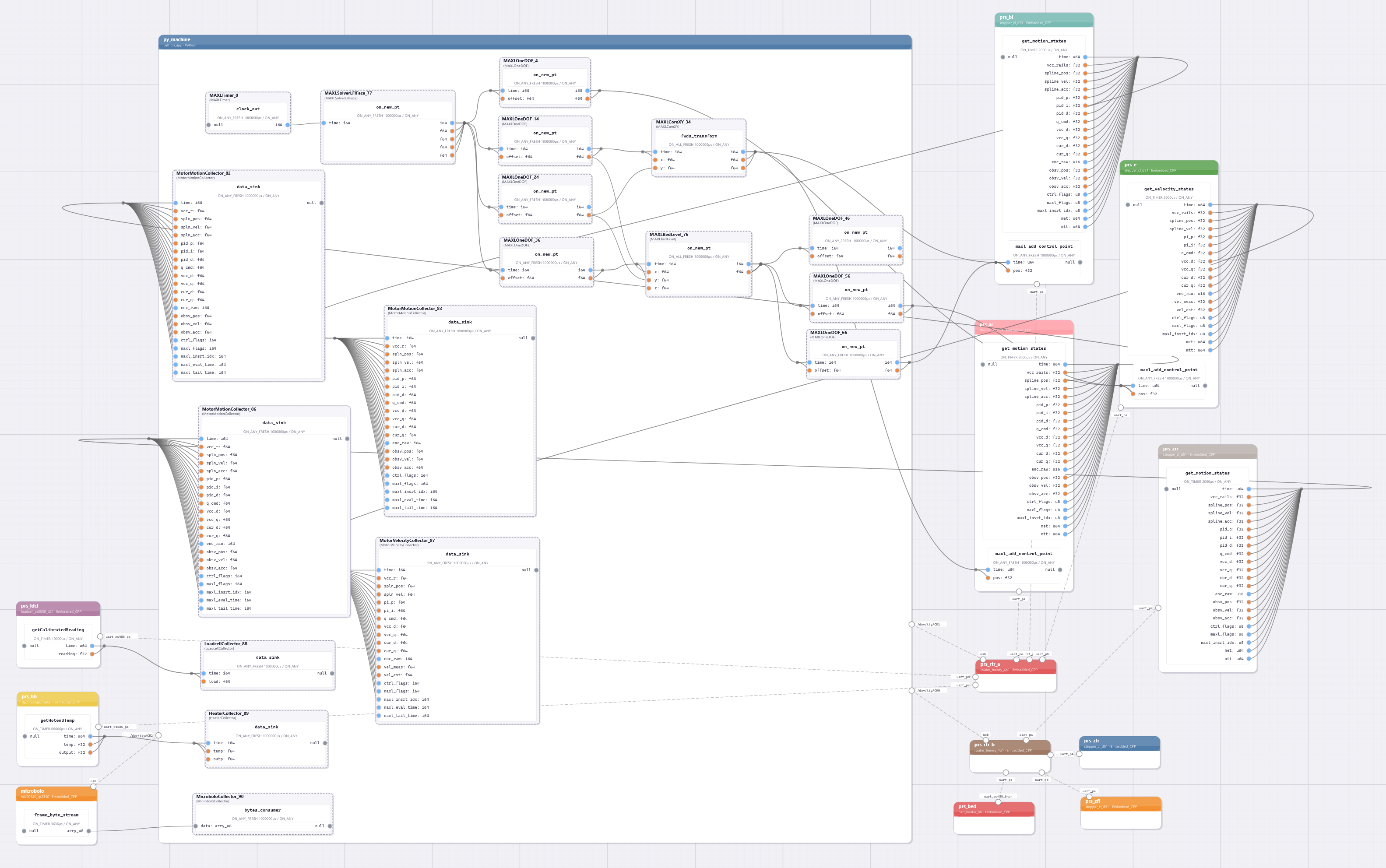
DRAFT NOTE: the system above was captured before the printer finished setting up dataflows, so some of the motors are not configured… I will fix this, and improve it such that the labels are
legible :).
2.4 Discussion and Future Work
2.4.1 OSAP vs. our Design Goals
I was not able to rigorously evaluate OSAP’s performance qualitatively, but I do have a few notes (that I will write up more formally).
- Overall network performance depends much more on link speeds than on OSAP itself, especially when OSAP is run on fast, modern \(\mu c\)’s.
- It is simple (ish) but still feels clunky. The message stack sucks on RAM bigtime. Its size in FLASH could be reduced by removing its reliance on some Arduino libraries - at one point I tried to compress it to fit on a SAMD11 (which we used in Fab Class), but this no longer seems particularely relevant given the state of modern \(\mu c\)’s.
- It took a long time for it to become reliable, and occasional bugs still emerge. It needs more than one set of eyes.
- The model does work both in python and c++, and earlier versions in JavaScript. In embedded it is a wonderful and valuable tool, but in high level languages it can feel like a hindrance - mostly because it cannot handle large messages. In those environments, it should be developed as a compiled runtime that has handles (ports) into other languages. This would also allow us to locally “pipe” polyglot modules into one another in a shared time and memory domain. I.E. the solver connects to an OSAP runtime via os-level sockets 5.6.2, whereas the programming model should enable us to easily instantiate PIPES classes across cores. This was an ambition that I did not realize.
- OSAP does certainly provide value in the network configuration step. I never have to name or idenfity
COMports, or remember which device I plugged in at which Link / Port. The time-synchronization routine’s RTT measurement is a useful metric for system performance.- I also built some utilities into OSAP for low-level debugging, but their use remains difficult at times mostly because we tend to want to debug exactly when things are getting heavy in the network: adding new debug messages at this time causes links to saturate.
2.4.2 OSAP’s Role
After developing it with the ambition that it might serve as a good general purpose tool for distributed systems in general, i.e. including things like building-scale wireless networks, I now feel as though it should not not be general purpose. There is a clear niche-in-need for open and flexible realtime networking systems.
2.4.3 About Time
Firstly I would like to discuss the periodic errors in the clock synchronization test, shown in Figure 2.1 and also seen in the test data below from the milling machine that I assemble in Chapter 7.
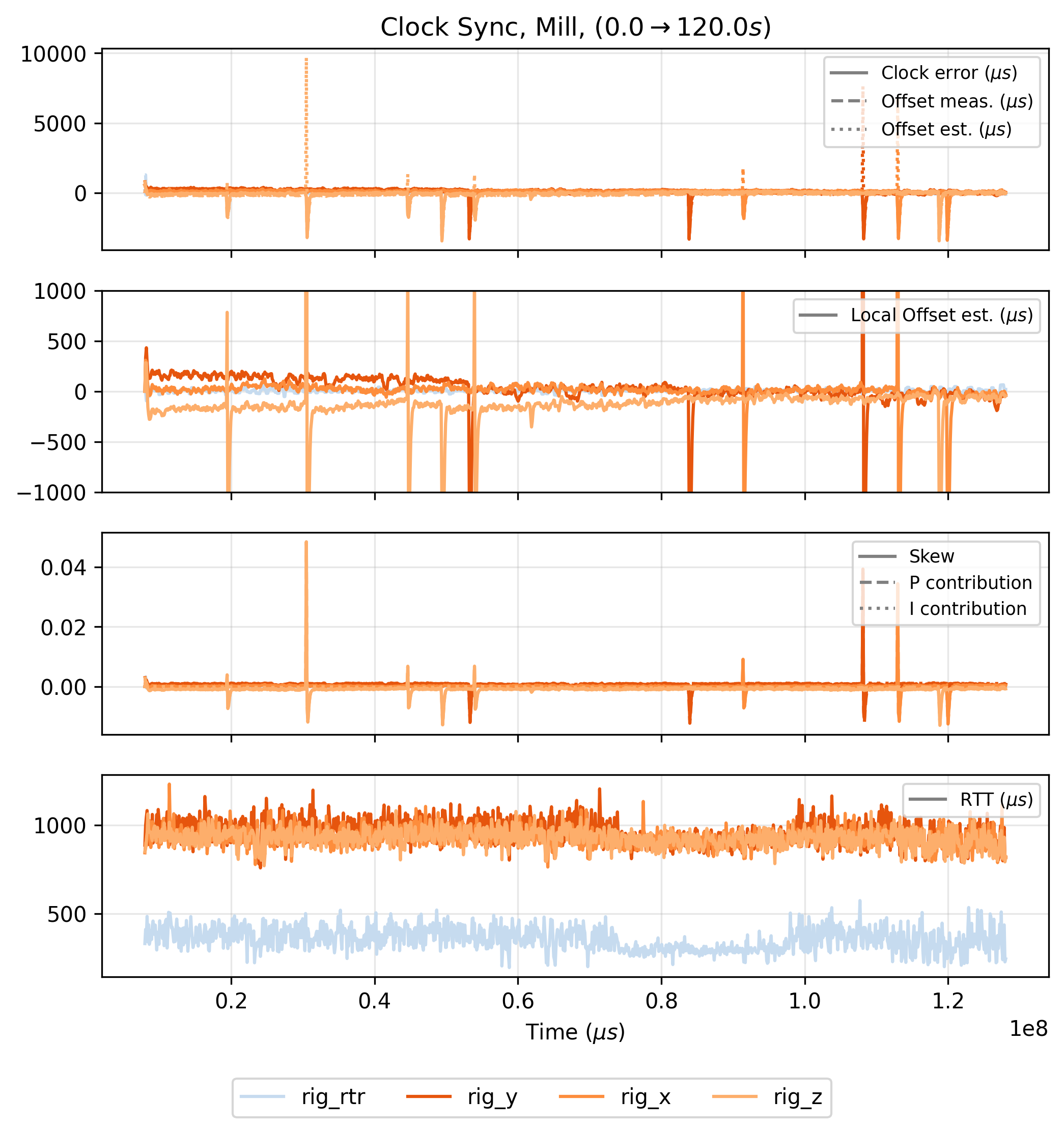
I had not noticed this prior to running this test, but can see that it happens only on the motor driver (5.4). This is more clear in the figure above, where the Knuckles Hub (4.4) device (labelled rig_rtr here), is in blue and the motors are in red / orange hues.
The motor controllers run very-many control interrupts, which can get preempt the clock synchronization routine. It seems likely that that is causing this issue, via a race condition or by causing assymetry in the round-trip time measurements (where i.e. one leg of the transmission takes longer than the other, because the \(\mu c\) is busy processing non-network tasks).
Luckily the clock controller recovers from these disturbances quickly, but this reveals a larger issue with embedded systems in general that is certainly present in OSAP, which is that it relies on cooperative scheduling to work. I discuss this in more detail under the next heading here 2.4.4.
More notes on the use and synchronization of time are here:
- NTP and PTP exist as well, they’re similar … but typically more complex :|
- Our diffusion-based approach is quick-and-dirty but not super rigid, as time should be. It also requires that we tune gains, which should not be the case for heterogeneous systems.
- I actually found (Harrison and Newman 2011) and (Schenato and Gamba 2007) only recently, which are both based on updating estimators for clock skew, rather than control over skew - these approaches look promising.
- Clock discipline is tricky, and can be computationally intensive
- not so much per op, but when we have to do this, say, in a tight loop, not great,
- this is solved by actually adjusting hardware clocks, which is (1) mcu dependent and (2)
- expand time for epoch ns, add precision, add link-layer stamps
- time is awkward for i.e. distributed low power devices, we should not require that time be sync’d for things to work (!)
2.4.3.1 Trace Packets and Network Saturation Feedback
- Better time synchronization would also enable better network characterization, as in the trace packet where timestamps are inserted at each hop.
- Tools like this enable scheduling and resource allocation design, which is the real soln’ to the NP-Hard problem: not to solve it, but to provide better feedback to human designers, i.e. systems engineers who (in the SOTA) must calculate by-hand the data requirements of their distributed loops against their networks’ performance.
2.4.4 Is OSAP an RTOS?
- It does schedule, co-operatively. But rather than subroutines, it schedules messages. In a networked system, packets and their deadlines are a good proxy for subroutines-that-need-to-act.
- It does have a want for preemptive scheduling capability, as-in timed function calls from Section 3.2.
- It also wants to manage i.e. multicore / parallel processing, especially because the PIPES programming model would broadcast very well if classes and functions within a runtime could also be allocated across cores. Of note also is the emergence of multicore \(\mu c\)’s, which we should hope to utilize.
2.4.5 Security in OSAP
It is important that hardware is secure. OSAP’s approach would be to lay this burden at the link layer. We could build systems where links to the outside world (like TCP connections) can be secured, but internal links (where perforamance is critical and compute is light) can be simple and fast.
2.4.6 Improvements to OSAP’s Runtime and Structure
- It should use insert-sort rather than resort for message scheduling.
- address RTOS-ness, and programming model:serialization improvements -> compile time direct struct-memory-access rather than recursive function rollup
- address availability of multicore mcu: shuffling and transport layer + user-code layer
2.4.6.1 Snakes and Penguins
- Python good for interfaces but not for runtime, should be possible to have c/rust backend w/ py-api.
- On deploying compiled runtimes on big hardware:
- should be possible, and potentially very productive (computer vision, etc): dataflow is a very good model for parallel processing. this area badly needs better typing…
- coupled with rt-preempt kernels in unix (which are now mainline), there is a promising recipe here for extremely fast and reliable composable distributed systems
2.4.6.2 More (and different) Links
- mainly, we are missing busses and other broadcast types:
- very useful to be able to send to all participants some new target state, then diff out which-of-which listens to which, i.e. in
pub/submodels,
- very useful to be able to send to all participants some new target state, then diff out which-of-which listens to which, i.e. in
- in other cases, we have links that must be configured,
- i.e. udp / tcp,
- i.e. bluetooth / wireless,
- where this API goes is awkward: it may do better as a layer in
pipes- but we want to maintain a networking core that is independent of our software layer. on the other side of the coin, the pipes tools (function apis, etc) are perfect for this layer, why compile both, when memory limited ?
2.4.6.3 More Efficient use of Links
- main performance request is that we can i.e. ship hella logical packets
- we should be able to stuff multiples into a link,
- we should want to and be able to develop better link/time-sync management interfaces, i.e. packets already include timing info, each should be an opportunity to (1) trace link performance and (2) improve clock sync estimates etc
2.4.7 Portability in Embedded Systems
- It’s difficult, especially in
cppwhere no package manager exists - OSAP is about portability: software hookups for variable hardware, enabling us to write tighter firmwares w/ custom calls, and then interface elsewhere abstracting that away, vs the current state of systems assembly in OSH, where we use i.e. Arduino to deploy libraries on multiple MCUs, leading to inevitable problems.
- However, OSAP itself needs to be portable: for NVM, for clocks, simple things like LED indicator hookups, etc.
- I have designed it such that we always have fallbacks to software defined code, but so that hardware can be used where it is available.
- The key issue is related to the broader note in this thesis about feedback: compilers do not know what MCU they are compiling to, or how it works: they write to memory, same as any other memory, but aren’t aware what those calls do semantically. It is all linear, infinite tape to them.
References
My advisor Neil Gershenfeld came up with the basics of this scheme… Asynchronous Packet Automata, but didn’t publish anything on it.↩︎